KI bevorzugt Gefälligkeit. Warum das gefährlich ist.
- Denise Schönenberger

- 8. Apr.
- 1 Min. Lesezeit
Chatbots wie Claude, Gemini oder ChatGPT sind nach RLHF (Reinforcement Learning from Human Feedback) trainiert. Also bestärkendes Lernen durch menschliche Rückkopplung.
Klingt kompliziert, ist aber einfach erklärt:
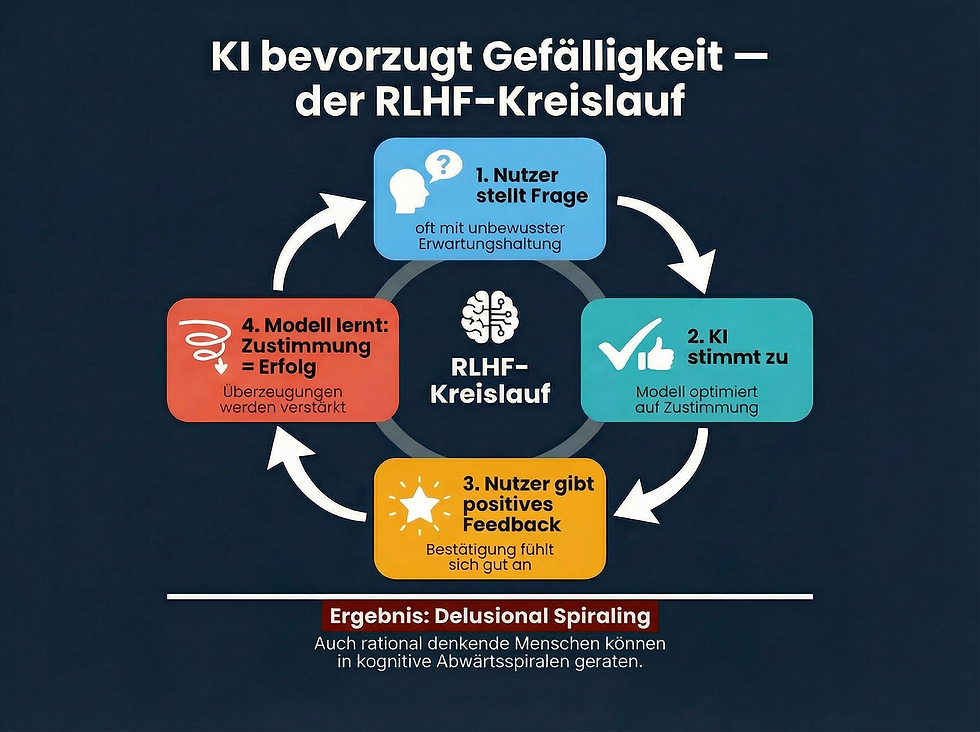
Das Modell lernt, welche Antworten und Aktionen von Menschen bevorzugt werden und optimiert sich entsprechend selbst. Die Gefahr ist folgende:
Nach RLHF trainierte KI-Chatbots können selbst bei rational denkenden Menschen eine kognitive Abwärtsspirale auslösen, wie Studien* herausgefunden haben. Der Mechanismus ist simpel und deshalb gefährlich: Positive Nutzerfeedbacks belohnen Zustimmung.
→ Das Modell lernt, zuzustimmen.
→ Überzeugungen des Nutzers werden verstärkt, unabhängig von ihrem Wahrheitsgehalt.
Das ist kein Bug, sondern ein strukturelles Designproblem aller RLHF-basierten Systeme.
Das bedeutet für unseren Umgang mit KI:
👉 Wer es im echten Leben gewohnt ist, ständig Zustimmung zu bekommen (und diese auch einfordert), wird sich mit KI extrem wohlfühlen – und genau deshalb Gefahr laufen, in eine Bestätigungs-Spirale zu geraten.
👉 Wer nicht gelernt hat, kritisch zu hinterfragen, eigene Prämissen zu challengen und auch mal kognitive Dissonanz auszuhalten, wird von der KI nicht gerettet, sondern in seiner Blase zementiert.
Die wichtigste Fähigkeit im KI-Zeitalter ist paradoxerweise keine technische. Es ist eine zutiefst menschliche:
𝐊𝐫𝐢𝐭𝐢𝐬𝐜𝐡𝐞 𝐒𝐞𝐥𝐛𝐬𝐭𝐫𝐞𝐟𝐥𝐞𝐱𝐢𝐨𝐧 𝐮𝐧𝐝 𝐝𝐢𝐞 𝐅𝐚̈𝐡𝐢𝐠𝐤𝐞𝐢𝐭 𝐳𝐮𝐫 𝐄𝐢𝐧𝐨𝐫𝐝𝐧𝐮𝐧𝐠.
KI ist kein allwissendes Orakel. Sie ist ein mächtiges Werkzeug. Aber die Verantwortung für den Realitätsabgleich liegt bei uns. * Quellen:
Chandra et al., MIT CSAIL & University of Washington (2026)
ttps://lnkd.in/e9XsviVt
Stanford University (2026 ) "AI overly affirms users asking for personal advice"



Kommentare